※ 자바에서 한글을 쓰기 위해서는 charset을 EUC-KR로 써라?!
자바를 배우기 위해 넉달동안 학원수강을 했다. 열심히 잘 배우고 이제 취직 준비중...
두 분의 강사를 만나 배웠는데.. 두 분 모두 한글 처리에 관해서는 이렇게 가르치고 있다.
“한글을 쓰려면 EUC-KR 인코딩을 사용해라...”
두 분의 강사 뿐만 아니라... 현재 국내의 JAVA 교육센터, 현재 출간된 자바, JSP관련 책자 등은 모두 한글처리를 위해서 EUC-KR 혹은 KSC5601을 사용한다고 나와있다.
문제는 왜 EUC-KR을 사용하는지에 대한 언급도 없으며, 한글 처리를 위해서는 MS949도 있고 UTF-8도 있는데 여기에 대한 언급도 전혀 없다. 단지 “한글 처리를 위해서” 란다. 강사조차도 MS949라는 인코딩 방식이 있는지 모르는 경우도 있으며, UTF-8에서 한글처리가 가능한 것을 모르는 경우도 있다. 이런 연유로... 현재 웬만한 PHP를 포함한 웹사이트들을 보면 EUC-KR로 인코딩이 되어있는 것을 확인할 수 있다.
EUC-KR이 온전한 한글이 아님은 이전에 내 블로그에서 확인한 바 있다. 2350개의 한글만 처리할 수 있는 이빨빠진 한글이다. EUC-KR을 사용할 바엔 차라리 MS949를 사용하는 것이 나을지도 모르겠다. 적어도 '뷁', '똠방각하'등의 글자를 제대로 처리하려면 말이다. 궁극적으로는 UTF-8를 사용해야 한다는 것이 내 생각이다.
물론 UTF-8을 사용할 경우 한글이 2바이트가 아닌 3바이트로 늘어난다는 단점도 있다. 그렇다고 UTF-16을 사용하기에는 웹문서의 대부분을 차지하는 ASCII 영역이 1바이트가 아닌 2바이트로 늘어난다.
그렇다면 왜 UTF-8인가?
첫째, FONT만 존재하면 외국 어느 국가에서든 인코딩 변환 없이 문서를 조회할 수 있다는 장점이 있다.
둘째, 한 문서 안에서 한글, 일본어, 한자 뿐만 아니라 세계의 모든 글자를 표현할 수 있다. 이는 곧 유니코드가 만들어진 배경이며 ISO표준이 된 이유이다.
셋째, 가장 중요한 이유로, 유니코드의 한글은 이빨빠진 완성형인 EUC-KR(KSC5601)뿐만 아니라 MS949 보다도 훨씬 정확하게 한글을 표현할 수 있다. MS949는 이전에 언급한 바도 있지만 정렬 문제가 치명적이다. 그러나 유니코드의 한글은 가~힣까지의 모든 한글이 순차적으로 배열되어있다. 덕분에 한글을 조합형처럼 분해, 조합할 때도 간단한 수식 계산만으로 가능하다고 이전에 포스팅한 적이 있다. 또한 “DB의 어떤 데이터를 사전 순서로 배열하라”고 하면 UTF-8기반으로 작성된 시스템에서는 “ORDER BY ... ”의 SQL문 하나로 끝날 수 있는 것이다. EUC-KR의 한글도 물론 순차적으로 배열되어 있지만, 한글 분해 조합을 위해서는 별도의 테이블이 필요하며, 유저가 “뷁”이라는 데이터를 요구하면 속수무책이다.
마지막으로, JAVA 내부적으로는 이미 UNICODE가 쓰이는데, 이를 억지로 EUC-KR로 바꾸느라 고생을 해야 한다는 점이다. 물론 이점은 Encode 관련 메소드에 의해서 UTF-8로 변환하나, EUC-KR로 변환하나 프로그래머가 직접적으로 느끼는 수고는 차이 없을지도 모르겠지만.
※ JSP, 톰캣에서 한글 사용하기
이하로 설명하는 것은 학원에서 EUC-KR 배운것을 UTF-8로 바꾸면서 경험한 것을 토대로 작성하였다. 톰캣 5.5 버전을 기본으로 설명하겠다. 다른 버전은 사용해보지 않았기에.
1. 기본 세팅의 톰캣
톰캣을 설치하면 기본 charset은 Latin-1(8859_1)으로 되어있다.
1) 페이지 설정
UTF-8을 쓰고자 하는 경우 *.html, *.htm, *.jsp 파일은 UTF-8 형식으로 저장한다.
EUC-KR, MS949는 ANSI, MS949등의 기본 형식으로 저장하면 된다.
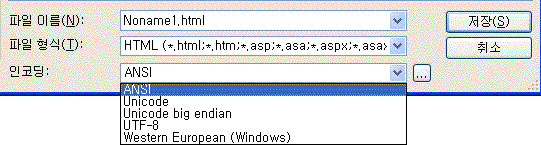
[그림] EditPlus에서의 저장 인코딩 옵션
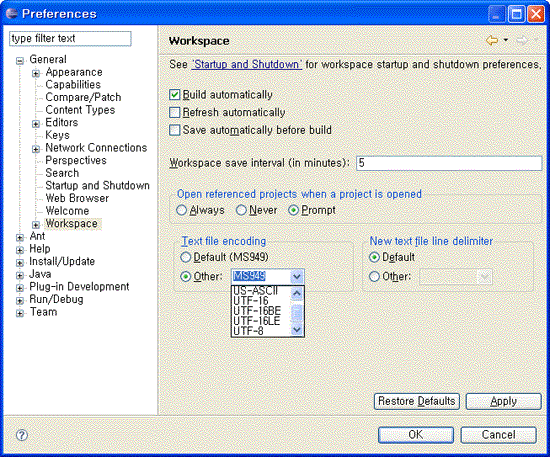
[그림] Eclipse에서 인코딩 세팅화면
모든 HTML, JSP에는 아래와 같은 META태그를 넣을 것을 권장한다.
<META HTTP-EQUIV="contentType" CONTENT="text/html;charset=UTF-8">
<!--EUC-KR인 경우 UTF-8을 EUC-KR로 바꾼다-->
JSP에서는 페이지 상단에 page 지시자를 다음과 같이 넣는다.
<%@ page contentType="text/html;charset=UTF-8" %>
<!--EUC-KR인 경우 UTF-8을 EUC-KR로 바꾼다-->
2) POST 방식의 데이터 전송
POST방식으로 전송된 데이터는 UTF-8이든, EUC-KR이든 다음과 같은 라인을 추가하면 해결 된다.
request.setCharacterEncoding("UTF-8");
//EUC-KR인 경우 UTF-8을 EUC-KR로 바꾼다.
3) GET 방식의 데이터 전송
GET방식으로 전송된 데이터는 URL을 통해 전송되기 때문에 위의 방식으론 쓸 수 없다. URL에서의 데이터를 Latin-1(8859_1)인코딩으로 서버에서 처리하기 때문이다. 이를 톰캣의 버그라고 단정짓는 일부 서적의 말은 잘못된것이다.
불러온 데이터를 아래와 같이 처리해 주어야 한다.
request.setCharacterEncoding("UTF-8");
String data = new String(request.getParameter("data").getBytes("8859_1"),"UTF-8");
//Latin-1(8859_1)로 읽어들인 데이터를 다시 UTF-8로 재해석하는 코드
//EUC-KR인 경우 UTF-8을 EUC-KR로 바꾼다.
4) 한글 파일 전송
Latin-1(8859_1)로 세팅된 톰캣 서버에서는 URL을 무조건 영어로 처리하므로 한글 파일은 절대로 읽어들일 수 없다. 파일을 영어로 바꾸어 저장하거나, 한글 파일을 영어로 바꾸는 처리를 해주어야 한다.
2. 톰캣의 세팅을 UTF-8로 바꾸기
톰캣의 conf라는 폴더를 보면 server.xml과 server-minimal.xml 이란 파일을 볼 수 있다. 텍스트 에디터로 열어서 <connector...>라는 항목을 찾아 다음과 같이 설정하자.
server.xml
<Connector port="8080" maxHttpHeaderSize="8192"
maxThreads="150" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true" URIEncoding="UTF-8" />
server-minimal.xml
<Connector port="8080" URIEncoding="UTF-8">
server-minimal.xml이 존재하지 않거나 server.xml만 바꾸었을때 제대로 동작하면 server-minimal.xml은 세팅할 필요 없다.
이 세팅은 웹페이지의 URL에서 문자열을 읽어올 때 서버가 처리하는 URL의 인코딩 타입을 변경하는 것이다. Internet Explorer에서 "URL을 항상 UTF-8로 보냄"이 켜져 있으면 브라우저는 서버에 UTF-8로 보낸다. 이를 서버에서 읽어들일때 UTF-8이 세팅되어 있어야 하는 것이다.
이제 기본세팅과의 차이점을 보자.
페이지 설정과 POST방식으로 전송된 데이터의 처리는 그대로 두어도 좋다. 서버를 UTF-8로 세팅한 만큼 가급적 UTF-8의 방식으로 페이지 설정을 하자.
GET방식으로 전송된 데이터의 처리는, 다음 항목이 필요가 없어진다. 당연하다. 있으면 오히려 에러가 발생할 것이다. 앞부분에 주석처리를 해버리자.
request.setCharacterEncoding("UTF-8");
//String data = new String(request.getParameter("data").getBytes("8859_1"),"UTF-8");//Latin-1(8859_1)로 읽어들인 데이터를 다시 UTF-8로 재해석하는 코드
한글 파일의 전송은 다음과 같이 처리한다.
<a href = "http://[server]:[port]/[folder]/<%= java.net.URLEncoder.encode( "한글파일.html" , "UTF-8" )%>">
한글파일 링크</a>
이렇게 하면 URLEncoder에 의해서 %xx%xx 형식의 UTF-8로 인코딩된 URL코드가 링크될 것이다.
그외에 Internet Explorer에서는 “URL을 항상 UTF-8로 보냄”이 기본 체크 되어있으므로 주소창에 한글을 직접 써도 서버에서 알아서 처리해준다. 물론 저 항목을 끄면 또 에러 발생.. (FireFox에서는 OS에 따라 MS949로 보낼 수도 있으므로 주의하자.)
3. 톰캣의 세팅을 EUC-KR로...
역시 conf 폴더에서 server.xml과 server-minimal.xml 이란 파일을 찾아 텍스트 에디터로 열어서 <connector...>라는 항목을 찾아 다음과 같이 설정하자.
server.xml
<Connector port="8080" maxHttpHeaderSize="8192"
maxThreads="150" minSpareThreads="25" maxSpareThreads="75"
enableLookups="false" redirectPort="8443" acceptCount="100"
connectionTimeout="20000" disableUploadTimeout="true" URIEncoding="EUC-KR" />
server-minimal.xml
<Connector port="8080" URIEncoding="EUC-KR">
server-minimal.xml이 존재하지 않거나 server.xml만 바꾸었을때 제대로 동작하면 server-minimal.xml은 세팅할 필요 없다.
역시 페이지 세팅은 서버가 EUC-KR인 만큼 EUC-KR로 하는 것이 바람직하다....(젠장)
GET방식으로 전송된 데이터의 처리는, 역시 다음 항목이 필요가 없어진다. 앞부분에 주석처리를 하자.
request.setCharacterEncoding("EUC-KR");
//String data = new String(request.getParameter("data").getBytes("8859_1"),"EUC-KR");//Latin-1(8859_1)로 읽어들인 데이터를 다시 EUC-KR로 재해석하는 코드
한글 파일의 전송도 마찬가지다.
<a href = "http://[server]:[port]/[folder]/<%= java.net.URLEncoder.encode( "한글파일.html" , "EUC-KR" )%>">
한글파일 링크</a>
뭐.. Internet Explorer에서 "URL을 항상 UTF-8로 보냄" 설정에 상관 없이 클릭하면 잘 될 것이다. 단.. 주소창에 직접 입력하려면 저 설정을 꺼야 된다.(개발자는 이를 고객에게 강요는 하지 말라. 어플리케이션 개발을 시작할때부터 한글을 직접 주소창에 입력하는 경우를 철저히 배제해야 한다.)
EUC-KR로 세팅한 이상 EUC-KR에서 지원하는 2350자 이외의 한글에 대해서는 보장이 되지 않는다. 차라리 MS949 방식을 권장하겠다.(EUC-KR과 거의 완벽히 호환된다! 거의 라고 말한 이유는 호환안되는 경우에 대한 확인을 못했기 때문에... 내가 알기론 없다.)
4. 서버세팅을 내가 못건드리는 경우
위에 한번 '젠장'이라고 한 이유가 여기에 있다. 현재 http://metalliza.kr을 호스팅 받고 있는 서버는 톰캣 세팅이 URIEncoding="EUC-KR"이 되어 있다.
하나의 서버를 다수의 유저가 EUC-KR로 사용하고 있기때문에 나혼자 UTF-8을 쓰겠다고 바꿔달라고 할 수가 없다. MS949로 바꿔달라고 하면 들어줄지는 잘 모르겠지만.
내 페이지 설정을 UTF-8로 해서 게시판 등의 어플리케이션을 작성했는데, 서버가 EUC-KR만 지원하기때문에 생기는 문제는 두가지.
첫째, 역시 KS완성형 2350자 이외의 한글은 지원되지 않는다.
둘째, GET방식으로 데이터를 넘기려고 할 경우 입력 FORM 안에서 데이터를 URL로 바꿀때 FORM 태그가 포함된 페이지의 인코딩 방식으로 넘긴다. 즉 UTF-8로 입력 FORM 양식을 열심히 만들어 놓고 전송버튼을 누르니 UTF-8로 데이터를 전송하려고 하는데 서버가 UTF-8을 인식못해서 엉뚱한 데이터를 받아들인다. 이게 가장 심각한 문제다! 사용자 페이지에서 서버측으로 직접 넘어가기 때문에 서블릿 명령을 적용할 새도 없다.
서버에 넘어온 값을 UTF-8로 바꾼답시고 아래 명령을 시도해봤지만... 실패.. EUC-KR로 바뀌면서 몇몇 값이 손실된다. 젠장!
String data = new String(request.getParameter("data").getBytes("EUC-KR"),"UTF-8");
//실패
이를 해결하려면 사용자 페이지의 자바 스크립트쪽에서 처리해서 넘겨야 할 것 같은데... 인코딩을 EUC-KR로 바꿔주는 자바 스크립트 내장 함수를 못찾고 있다. 하는 수 없이 자바스크립트 함수를 직접 만들었더니... 라인수가 약 18000개에 용량이 500KB에 달하는 엄청난 자바스크립트가 나왔다. EUC-KR의 모든 캐릭터를 일일히 매핑해주어야 하기 때문이다. 이걸 적용해야 하는지는 의문이다.
일단은 게시판 프로그램을 완성하고 두고봐야겠다.
[출처] EUC-KR vs. UTF-8 ( 자바에서 한글을 처리하는 법 )|작성자 메탈리쟈