programming/python

[Python] keras를 활용한 뉴스분류 실습
43. keras를 활용한 뉴스분류 실습 41.1 실습예제 # 케라스 로딩 import keras keras.__version__ # 뉴스 기사 분류: 다중 분류 문제 # 로이터 뉴스를 46개의 토픽으로 분류하는 신경망(다중분류) ## 로이터 데이터셋 # 1986년에 로이터에서 공개한 짦은 뉴스 기사와 토픽의 집합인 데이터셋(케라스 내장 데이터셋) # 텍스트 분류를 위해 널리 사용되는 간단한 데이터셋 # 46개의 토픽 # 각 토픽은 최소 10개의 샘플이 있음 # 데이터 다운로드 from keras.datasets import reuters # 자주 등장하는 단어 10,000개로 제한 (train_data, train_labels), (test_data, test_labels) = reuters.load_..

[Python] keras를 활용한 영화리뷰 분석
42. keras를 활용한 영화리뷰 분석 42.1 실습예제 # 영화 리뷰 분류(이진분류) # 영화 리뷰를 긍정, 부정으로 분류 import keras keras.__version__ ## IMDB 데이터셋(케라스에 내장된 데이터셋, 숫자로 전처리되어 있음, 17MB 정도의 데이터셋) # 영화 리뷰 50,000개의 데이터셋 # 학습용 데이터 25,000개와 검증용 데이터 25,000개, 각각 50%는 부정, 50%는 긍정 리뷰로 구성 # num_words=10000 가장 자주 나타나는 단어 10,000개만 사용, 드물게 나타나는 단어는 무시 # train_data, test_data: 리뷰의 목록 # 각 리뷰는 단어 인덱스의 리스트(단어 시퀀스가 인코딩된 것) # train_labels, test_labe..

[Python] 오토인코더(keras)
41. 오토인코더(keras) 41.1 오토인코더(autoencoder) 41.1.1 주성분분석으로 처리하는 일차원 데이터 처리 방식을 딥러닝 방식으로 확장하는 방식으로 비지도학습 방법 41.1.2 다차원 입력 데이터를 저차원 부호로 바꾸고 다시 저차원 부호를 처음 입력한 다차원 데이터로 바꾸면서 특징점들을 찾아내는 방식 41.1.3 핵심적인 정보만을 남기고 사람이 잘 느끼지 못하거나 둔감한 정보는 손실시키는 압축 방식, 출력값은 입력값의 근사치(노이즈가 있는 데이터가 주어졌을 때 노이즈를 제거하여 원래의 데이터를 재현하는데 사용되는 모델) 41.1.4 부호화 과정 41.1.4.1 입력층에 들어온 다차원 데이터가 차원을 줄이는 은닉층으로 입력됨 41.1.4.2 은닉층의 출력이 부호화 결과 41.1.5 복..

[Python] 합성곱 신경망(CNN)
40. 합성곱 신경망(CNN) 40.1 CNN 40.1.1 이미지를 작은 구역으로 나누어 부분적인 특징을 인식하고 이것을 결합하여 전체를 인식하는 알고리즘 40.1.2 이미지 인식에 성능이 뛰어나며 최근 텍스트 분류에도 많이 사용되고 있음 40.1.3 텍스트 데이터를 word2vec을 적용하여 벡터로 변환한 후 CNN에 입력하여 분석하는 모델 40.2 실습예제1(이미지 분류-mnist) # 합성곱 신경망 # MNIST 숫자 이미지 분류에 CNN 사용 # (image_height, image_width, image_channels) 크기의 입력 텐서를 사용 # 첫 번째 입력층의 매개변수로 input_shape=(28, 28, 1) 전달 import keras keras.__version__ from ker..

[Python] DNN(Keras)
39. DNN(keras) 39.1 실습예제(mnist) # 필기체를 분류하는 DNN 구현 # 심층신경망(Deep Neural Network, DNN) 은닉층을 많이 쌓아서 만든 인공신경망 # 학습데이터가 적거나 복잡한 이미지에 더 우수한 성능을 보이는 기법 %matplotlib inline import numpy as np import pandas as pd import os from keras.utils import up_utils from keras import layers, models, datasets # seaborn import seaborn as sns sns.set(style = 'white', font_scale = 1.7) sns.set_style('ticks&#..

[Python] 인공신경망 실습(Keras)
38. 인공신경망 실습(keras) 38.1 실습예제1(기초적인 인공신경망) # 케라스 패키지 임포트 from keras.models import Sequential from keras.layers import Dense import numpy as np # 입출력 데이터 # 딥러닝 모델에 입력할 값 x = np.array([0, 1, 2, 3, 4]) # 출력값: x * 가중치 + 편향 y = x * 2 + 1 print("x: ", x) print("y: ", y) # 인공신경망 모델링 # 케라스 인공신경망 생성 model = Sequential() # 입력노드 1개를 가지는 선형처리계층 추가 model.add(Dense(1, input_shape = (1,))) # 모델 컴파일, 확률적 경사 하강법..

[Python] 회귀분석(keras)
37. 회귀분석(keras) 37.1 케라스(keras) 37.1.1 케라스의 개요 파이썬으로 구현된 쉽고 간결한 딥러닝(deep learning) 라이브러리 구글의 엔지니어인 프랑소와 숄레(Francois Chollet)가 2015년 3월에 발표 최근 버전: 2019년 10월 현재 2.3.0 내부적으로는 텐서플로우(tensorflow) 엔진이 구동되지만 직관적인 API로 쉽게 딥러닝 실험을 할 수 있도록 지원함 37.1.2 케라스의 주요 특징 모듈화(Modularity): 독립적인 모듈들을 조합하여 구현 최소주의(Minialism): 각 모듈은 짧고 간결 쉬운 확장성: 클래스나 함수로 모듈을 쉽게 추가할 수 있음 파이썬 기반: 별도의 설정이 필요없음 37.1.3 케라스 설치 pip install ker..

[Python] Tensorflow 실습
36. Tensorflow 실습 36.1 TensorFlow의 주요 개념 36.1.1 오퍼레이션(Operation) 그래프 상의 노드 하나 이상의 텐서를 받을 수 있음 계산을 수행하고 결과를 하나 이상의 텐서로 리턴 36.1.2 텐서(Tensor) 일종의 다차원 배열 내부적으로 모든 데이터는 텐서를 통해 표현됨 그래프 내의 오퍼레이션 간에는 텐서만이 전달됨 36.1.3 세션(Session) 그래프를 실행하기 위해서 필요한 객체 36.1.4 변수(Variables) 그래프의 실행 시 파라미터를 저장하고 갱신하는데 사용됨 메모리 상에서 텐서를 저장하는 버퍼 역할
[Python] Tensorflow 기초
35. Tensorflow 기초 35.1 머신러닝 / 인공지능 35.1.1 인간이 코딩 등으로 사전에 정의 내린 행동이 아닌 행동을 하도록 하는 것에 가까운 개념(Arthur Samuel, 1959) 35.1.2 스팸필터, 상품추천, 자율주행차 등의 다양한 분야에서 활용되고 있음 35.1.3 머신러닝은 러닝, 즉 "학습"의 개념이 포함됨 35.2 학습 머신러닝을 코딩한다는 것은 결국 "학습"하는 방법을 코딩한다는 것 어떻게 학습을 시킬 것인가? = 어떻게 시행착오를 거치게 할 것인가? 35.2.1 어떤 목표를 정해 놓고 목표를 달성하게 할 경우 의도된 결과를 도출하도록 하는 것 35.2.2 손실 함수, 비용 함수(cost function, loss function) 학습을 통해 그 값을 최소로 만드는 것..
[Python] Java와 Python 연동
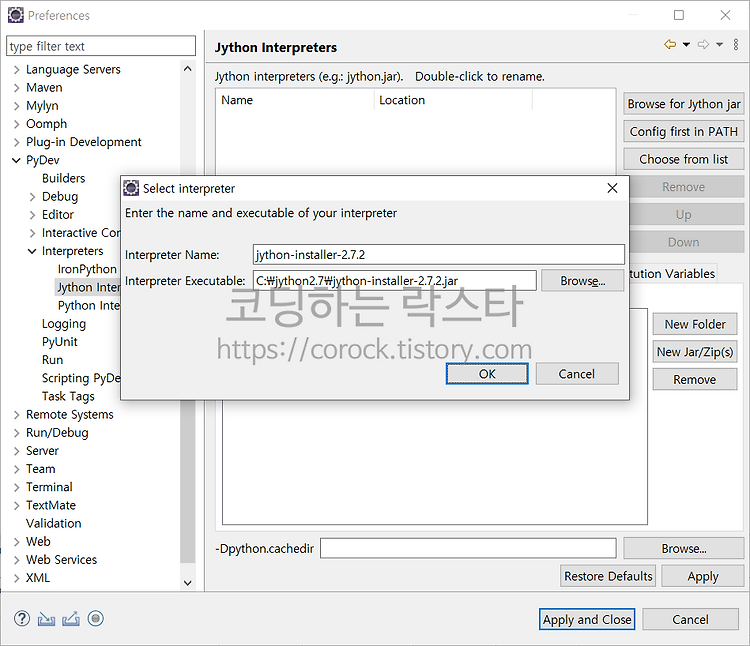
34. Java와 Python 연동 34.1 Java에서 Python 명령어를 실행하는 방법 34.1.1 Jython Python 2.7 기준의 문법이 적용됨 numpy, pandas 등의 외부 라이브러리 사용이 어려운 단점이 있음 34.1.2 JEP 34.1.3 pyro4 34.1.4 Java에 내장된 Process 명령어를 사용하는 방법 34.2 Jython 설치 Jython 2.7.2 Installer 버전 다운로드 및 설치 다운로드받은 python-installer-2.7.2.jar 파일을 더블 클릭하여 기본 옵션으로 설치함(설치 디렉토리는 C:\jython2.7로 통일) 프로젝트 경로에 한글이 포함되어 있으면 아래와 같은 에러가 발생함 Cannot create PyString with non-b..

[Python] Clustering, KNN
33. Clustering, KNN 33.1 분류의 2가지 종류 33.1.1 Classification 33.1.2 Clustering 33.2 군집분석(Clustering)의 원리 33.2.1 거리가 가까운 (유사도가 높은) 개체들을 서로 묶어 하나의 그룹으로 정리 33.2.2 거리(유사도)의 계산방법 유클리드 거리(Euclidean distance)가 주로 사용됨 맨해튼 거리(Manhattan distance) 33.2.3 군집화 방법 33.2.3.1 계층적 군집화 방법 Hierarchical method 33.2.3.2 비계층적 군집화 방법 K-means clustering(비지도학습, Unsupervised Learning) 33.3 K-means 군집화의 실행단계 33.3.1 나누고자 하는 클러..
[Python] SVM(Support Vector Machines)
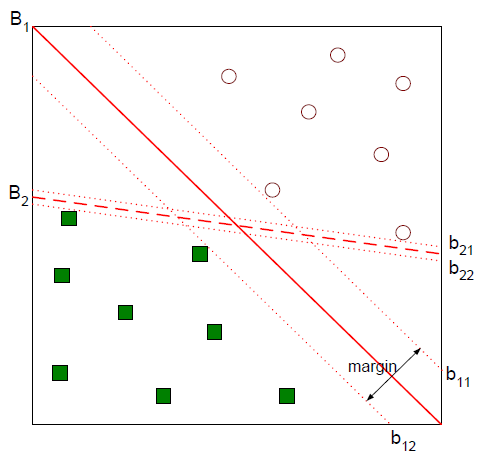
32. SVM(Support Vector Machines) 32.1 개요 32.1.1 예측 기법 Boser, Guyon 및 Vapnik에 의해 1992년 제안된 이후, 1990년대 후반부터 현재까지 학계와 업계(주로 미국 및 유럽 선진국)에서 활발하게 활용되고 있는 예측 기법 32.1.2 기계학습의 분야 기계학습의 분야 중 하나로 패턴 인식, 자료 분석을 위한 지도학습 모델 32.1.3 용도 주로 분류와 회귀 분석을 위해 사용됨 32.1.4 알고리즘 두 카테고리 중 어느 하나에 속한 데이터의 집합이 주어졌을 때 새로운 데이터가 어느 카테고리에 속할지 판단하는 기준으로 가장 큰 폭을 가진 경계를 찾는 알고리즘 직선 B1과 B2 모두 두 범주를 잘 분류하고 있음 B2보다는 B1이 두 범주를 여유있게 분류하고..